We are proud to announce that Scailable has been acquired by Network Optix.
For the announcement on the Network Optix website, move here.
Apples and Oranges II: The Forgotten Metric
In an earlier post we described the performance of the Scailable AI manager in terms of computational speed. While this is an interesting metric, in many ways a solution only has to be “sufficiently fast”; once this is the case other metrics become much more important. Power consumption might be one (and is one we are actively working on). Another metric, often forgotten, is the engineering effort involved in creating and maintaining the edge AI solution. We examine this latter metric in more detail in this post.
The Edge AI lifecycle
To consider the engineering effort involved in creating an Edge AI solution one has to start by considering the Edge AI training and deployment cycle. The following figure provides an overview:
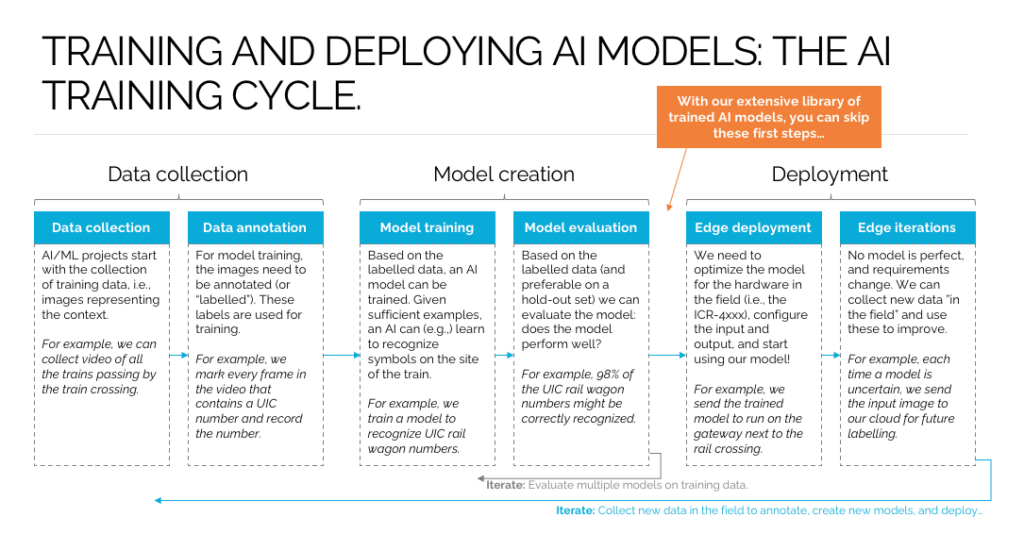
Simply put, when creating and managing an edge AI solution, one goes through (and often iterates through) the following steps:
- Data collection
- Data annotation
- Model training
- Model evaluation
- Edge deployment
- Edge updates / iterations
With Scailable we focus on the latter two stages (5 & 6): given a trained model, how does one move it to an edge device (and how does one make sure the model stays up-to-date)? These two stages involve a number of highly challenging engineering tasks:
- Deployment: Give the target device, one often needs to start with installing the necessary tools on the target device. Depending on the familiarity with the target device this might be fast (you might have an image available), or this might take hours of sorting through challenging documentation and compiler hell.
- Deployment: Given a trained AI/ML model, one needs to create (often code-up) the logic to grab sensor data, feed it into the model, and process the output. The engineering involved in creating such a pipeline for a target device is challenging, especially when resources on the device are constrained.
- Deployment: Given a trained AI/Ml model, one needs to “convert” the model to a format that runs on the selected edge device. Sometimes this is easy: if you are storing a model in ONNX format, and the target device is sufficiently large to host the ONNX runtime, this is simply a matter of installing, configuring and testing (still a process that can take hours, but hey, its not technically hard). However, we often find much more challenging conversions where effectively a whole model needs to be reimplemented in a new language to be able to allow for compilation towards to the target device.
- Updates/Iterations: Given iterations of the model (i.e., as time goes by you might improve your model), one will need to update the model. Hence, it is often necessary to replace the software running on the device.
Note that none of the above are tasks commonly done by data scientists or AI/ML engineers.
The time involved in creating and managing Edge AI applications
It is relatively easy to provide a “ballpark” figure of the time usually spend for each of the steps above. Below we provide a (highly) conservative estimate for the time that is consumed when creating and managing (with 2 model updates a year) a fleet of 100 (identical) edge AI devices:
- Let’s assume it takes roughly 24 hours (3 days) to sort out the image on a single device. Let’s further assume this image can be copied within 30 mins to each of the other devices. So that totals roughly (24 + 100*1/2) = 74 hours.
- Let’s assume it take roughly 5 engineering weeks to code up the complete model pipeline on the target device. That’s roughly 180 hours. And let’s be very friendly here and say that this pipeline can be copied to the devices with the software update in point 1 above so scaling to all devices does not costs you extra.
- Let’s assume you took a model in a format that can simply be copied to the device. So, although often this process can actually take weeks, let’s be extremely gentle and count 0 hours.
- Finally, let’s assume that twice a year you update all of the devices with a new model. Let’s give it 2 hours of configuration per device per model update, thus calculating roughly 2*2*100 = 400 hours.
Well, over the course of a year this effectively lower-bounds the engineering involved in creating and managing an edge AI solution across 100 devices at 74+180+400 = 654 hours. An experience engineer (one that might be able to actually do the tasks above in the hours projected) will at least set you back $100 dollars an hour. So, that’s (and again “lower bounding the at least” here) $65.400,-.
Now, with Scailable things are very different. You can buy edge devices with the Scailable AI manager pre-installed (yes, that saves you all of step 1 and step 2). You can simply configure your model using the Scailable platform, and, over-the-air, update the model to a group of devices in one go. This will take you about 30 mins tops. Ok ok, so that’s 1 hour for the bi-yearly model updates. However, that simply supports the final conclusion that you can use the Scailable platform, and the Scailable AI manager installed on each of the 100 devices, for a fraction of the original engineering cost.
Interested; book a demo!

Why We Are Joining Network Optix
Today, the entire Scailable team is joining Network Optix, Inc., a leading enterprise video platform solutions provider headquartered in Walnut Creek CA, with global offices in Burbank CA, Portland OR (both USA), Taipei Taiwan (APAC HQ), Belgrade Serbia, and shortly in Amsterdam (EU HQ). Network Optix, since its founding, has set out to “solve” video […]

Scailable supporting Seeed NVIDIA devices
We are excited to announce support for Seeed’s NVIDIA Jetson devices. The AI manager, and all our edge AI development tools, can now readily be used on Seeed devices. As we all know, edge AI solutions often start from creative ideas to optimize business processes with AI. These ideas evolve into Proof-of-Concept (PoC) phases, where […]
From your CPU based local PoC to large scale accelerated deployment on NVIDIA Jetson Orin.
Edge AI solutions often start with a spark of imagination: how can we use AI to improve our business processes? Next, the envisioned solution moves into the Proof-of-Concept (PoC) stage: a first rudimentary AI pipeline is created, which includes capturing sensor data, generating inferences, post-processing, and visualization of the results. Getting a PoC running is […]